My first go at Machine Learning with AWS DeepRacer
This is a raw first look as someone with absolutely no machine learning experience detail exactly what I learnt from AWS DeepRacer and it's training as I did it. Let’s see how I went.

What is reinforcement learning?
Reinforcement learning (RL) is a type of machine learning, in which an agent explores an environment to learn how to perform desired tasks by taking actions with good outcomes and avoiding actions with bad outcomes. A reinforcement learning model will learn from its experience and over time will be able to identify which actions lead to the best rewards
Wait what?
If you’re like me, you’ve heard about machine learning and AI and if you work in IT like I do, everyone seems to want some (even if they don’t know why or what it does).
I’ve always been interested in what machine learning and AI can do (especially in the real world with stuff like computer vision) but every time I’ve looked into it, watching people build some things on YouTube is about as far as I got before it all seemed a little too hard. After all, don’t you have to be some hardcore software developer to do this stuff? Not an infrastructure architect like me.
Now I’ve known about AWS DeepRacer for some time, it was announced at re:Invent 2018. One of the guys from work even got one at the time but you know how things go, other things need to get done and you forget about it.
Well as I sit here now, avoiding cleaning my office I though let’s give it a go, after all AWS has some free training and it even says on the front page for DeepRacer
Get started with machine learning quickly with hands-on tutorials that help you learn the basics of machine learning, start training reinforcement learning models and test them in an exciting, autonomous car racing experience.
Sounds better then cleaning!
Disclaimer
This is a raw first look as someone with absolutely no machine learning experience detail exactly what I learnt from the training and trying AWS DeepRacer as I did it, the information below could be completely wrong but is what I learnt, if you spot something wrong feel free to comment and let me know so we can all learn together!
Creating my first model
Model Configuration
The training gives you a bit of an overview of DeepRacer and then gets you straight into building your first model. Following the training our first model is basically going to be using the defaults.
Model Name and Environment
First, we give it a name
and then select the re:Invent 2018 Track

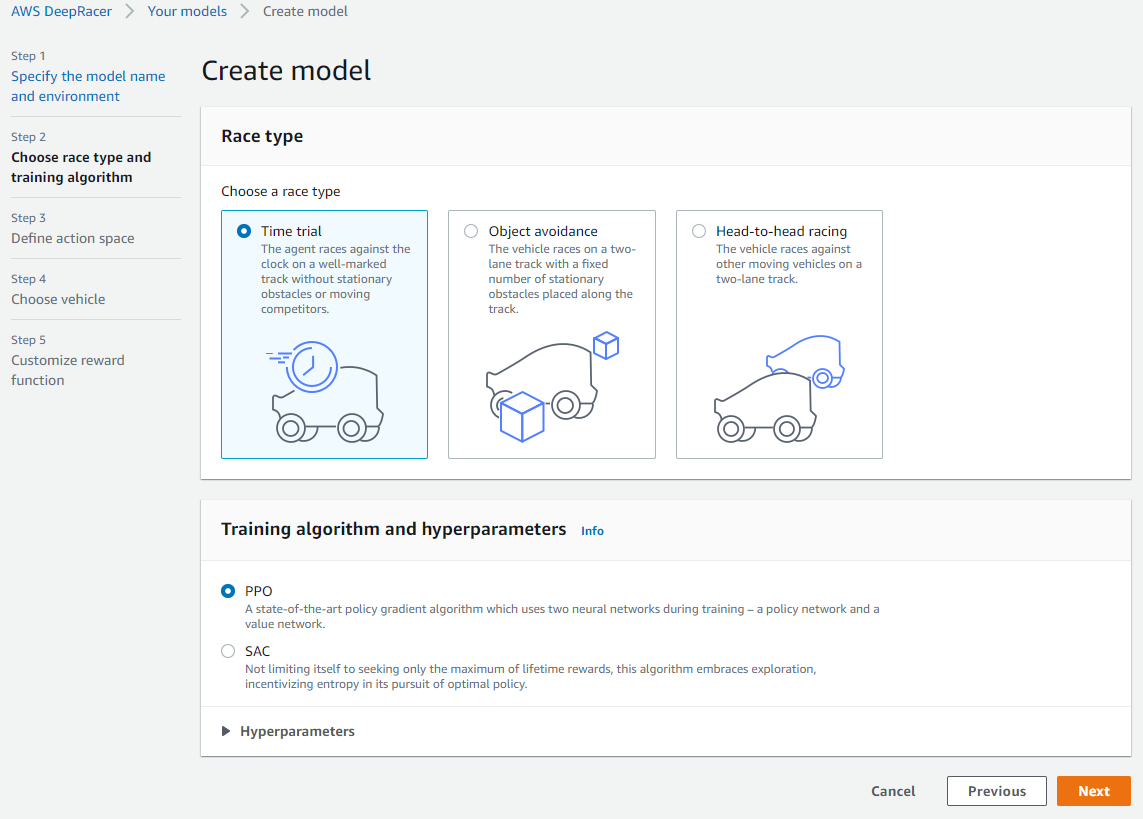
Race Type and Algorithm
Now the training document was a little out of date from the console, so I left it with the defaults selected for the race type and algorithm and then continued.
Some definitions to help
Now the console and training started to use quite a few words I had never heard of before and if you don’t know them this blog post might get confusing so I will try and summarise them from the training material.
In reinforcement learning, an agent interacts with an environment with an objective to maximise its total reward. The agent takes an action based on the environment state and the environment returns the reward and the next state. The agent learns from trail and error, initially taking random actions over time identifying the actions that lead to long-term rewards
- Agent – The agent is the DeepRacer (or more specifically the neural network that makes it do things based on inputs and then deciding actions)
- Environment – The environment is where the track is and thus defines where the agent can go and what state it can be in. The agent moves around the environment to train the neural network
- State – A state is a point in time snapshot of the environment, with DeepRacer this is what the camera sees
- Action – An action is a move made by the agent in the current state. With DeepRacer this is speed and steering angle
- Reward – So the agent knows if it done something good or bad, a reward is the score given to the agent when it takes and action in a given state. This is generally called the reward function
Reinforcement learning is basically like training your dog. If it does something good, you reward it with a treat. But if it does something bad, no treat.
Action Space
Next, we define our Action Space
- Action Space – An action space is all the valid actions that is available to the agent in the environment
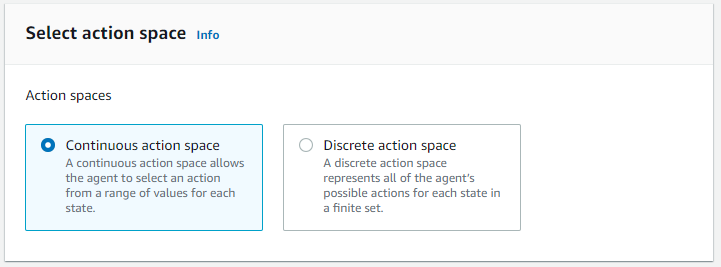
With DeepRacer we can select a Continuous or Discrete action space.
Now I had to do a little bit of reading to understand this (at least I think I do) but basically the difference is from what I can tell is:
Continuous action space (the default and what we will be selecting)
With Continuous action space you set the min/max settings that the agent can choose to use during the training, and it uses these ranges when taking actions to learn the best settings to use during the training. With DeepRacer this means we set the steering angle and speed ranges.
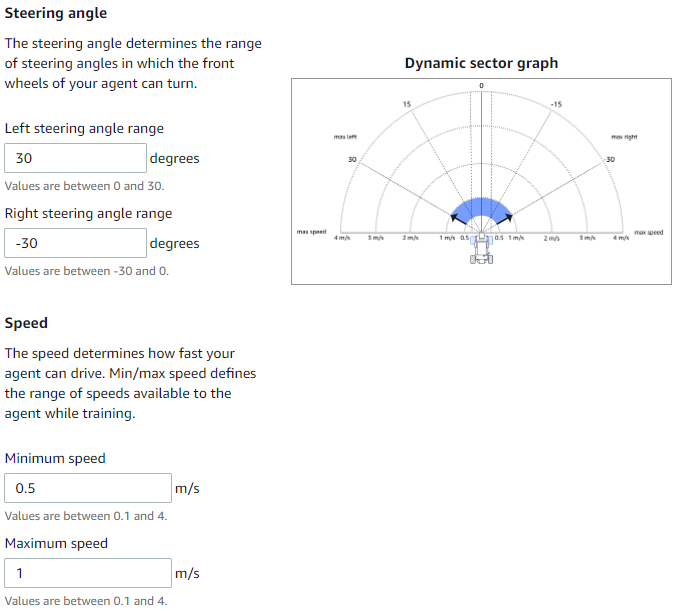
Discrete action space
You specify the specifics of each action (steering angle and speed) that the agent can use during the training.
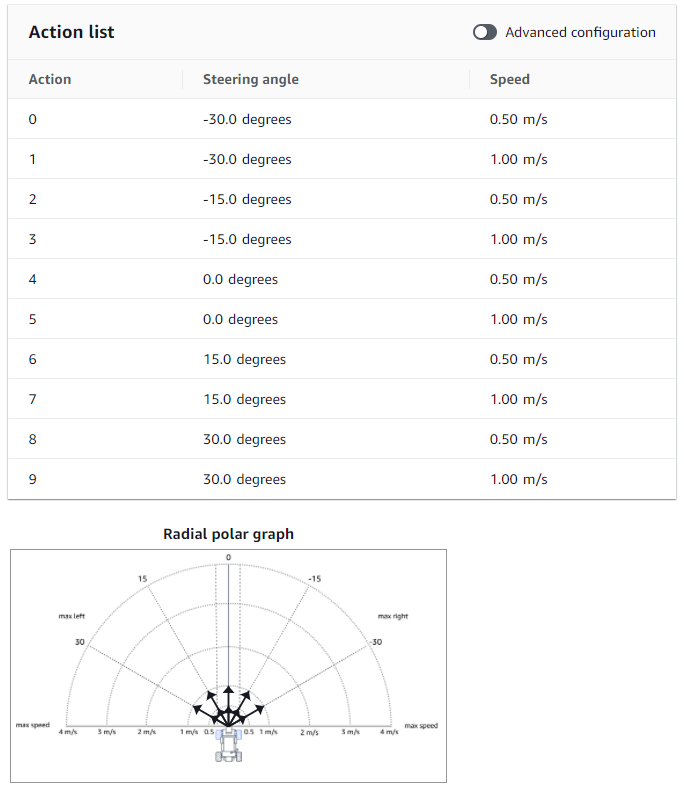
Discrete vs Continuous
From what I can tell in my 10 minutes of experience, continuous might produce better results as the agent is allowed to learn using all the options in the range. However, the downside is the agent has to train longer to figure out what is the best action to use at the time.
Vehicle Selection
Next we select our Vehicle and we can only select the one vehicle which is the Original DeepRacer
Reward Function
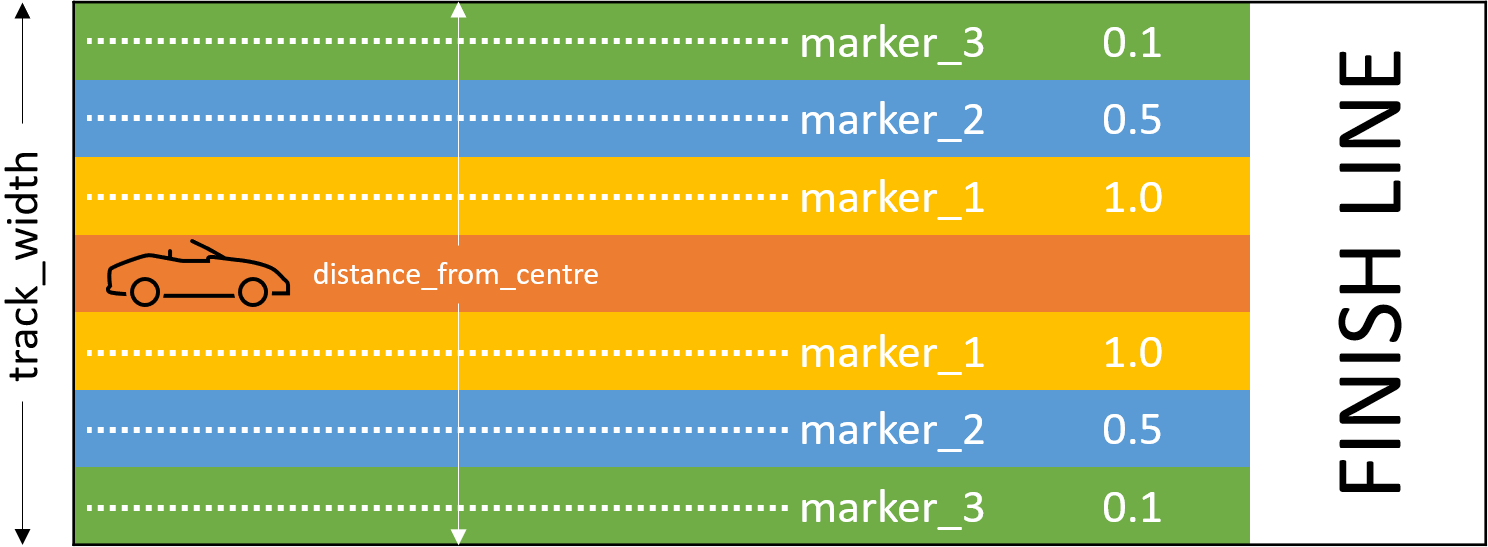
Next up, Reward Function. As described above, the reward function gives the agent feedback on its action as a score. The training is a little out of date here again, but we will just continue with the defaults. This reward function rewards the agent based on its distance from the centre line on the track.
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
Stop Condition
We then set a stop condition, so we don’t end up with a large AWS bill.
Model Created
Now that's the last configuration we will be doing for our first model. Once we’ve clicked Create Model, our training is started.
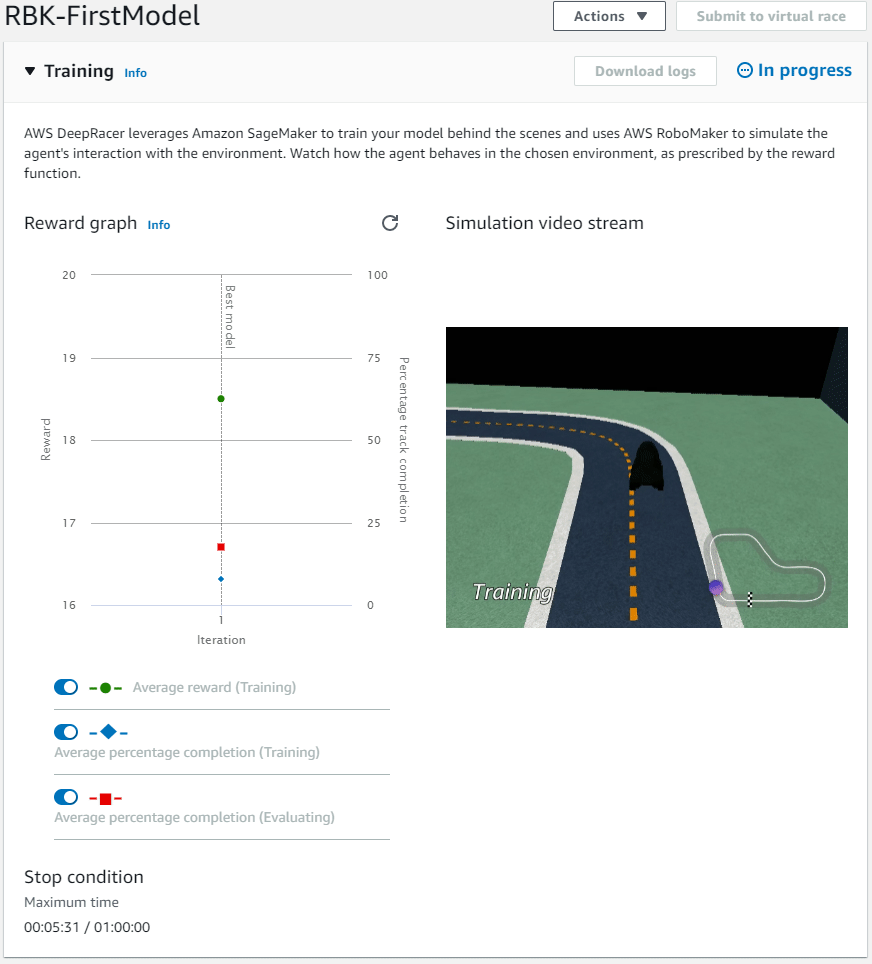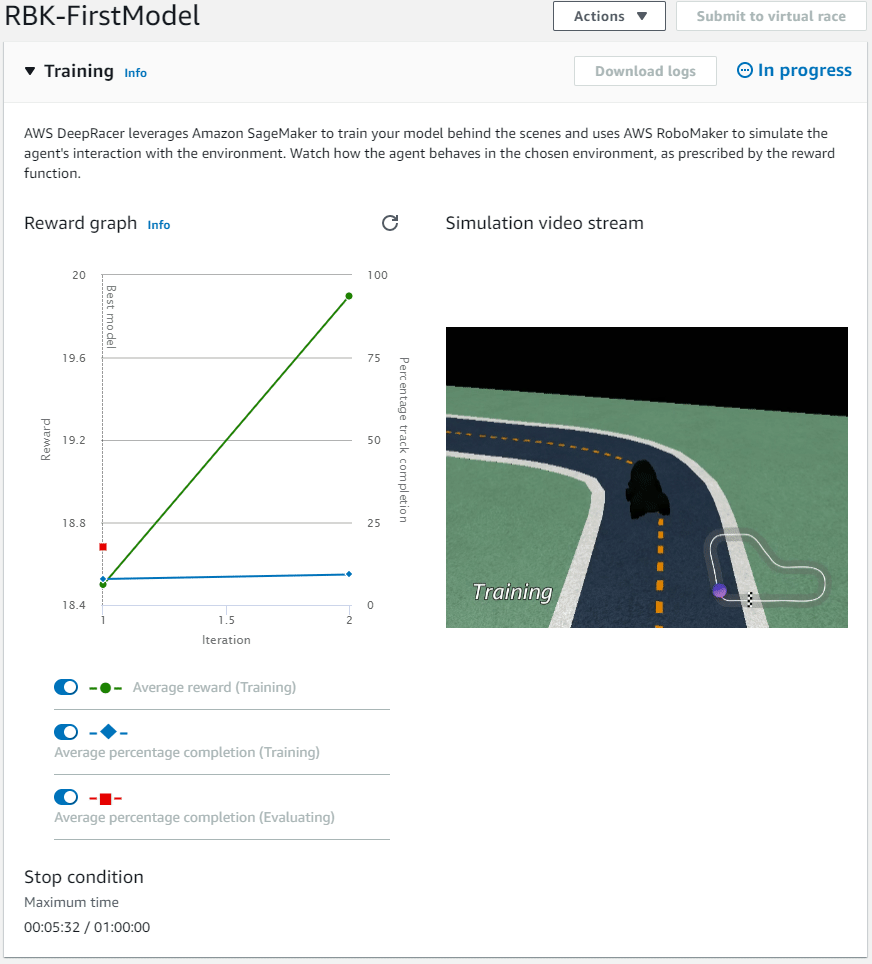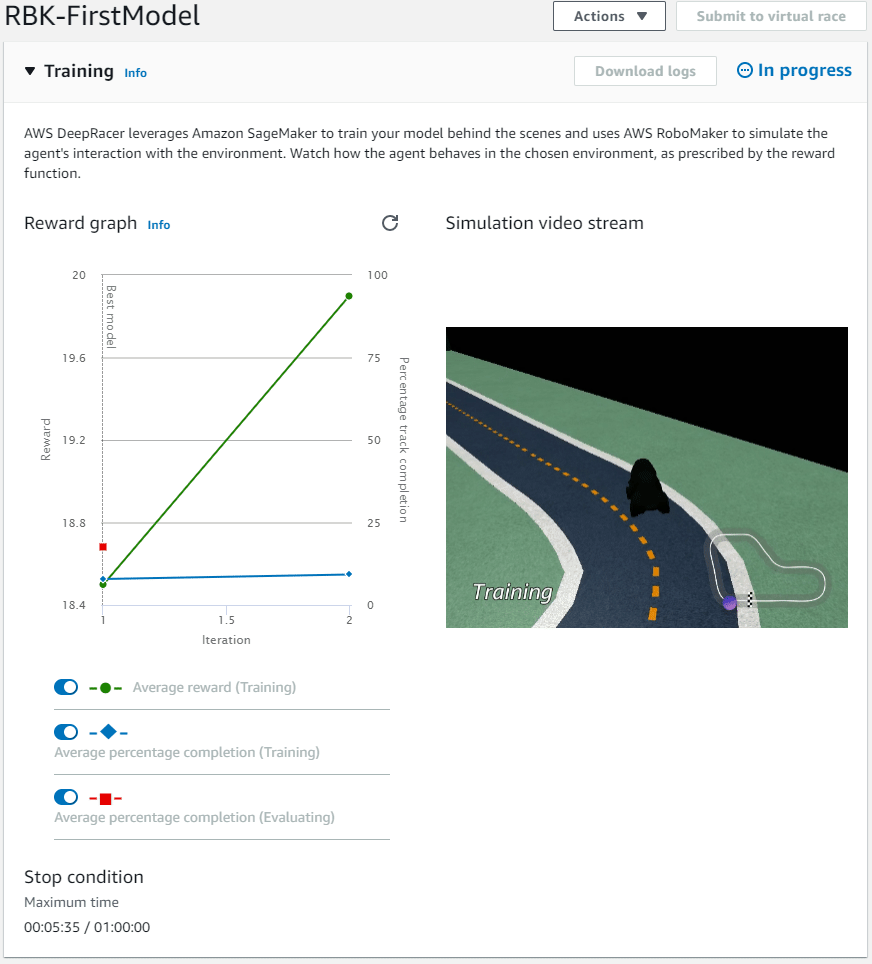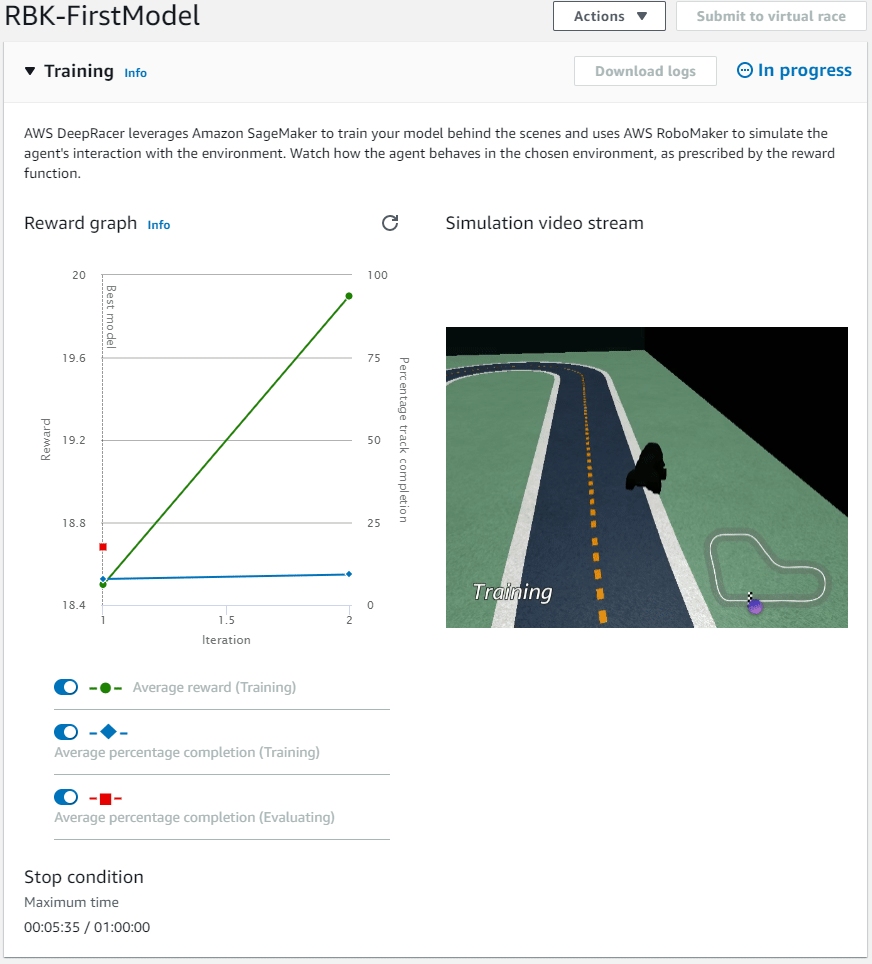
Training
The training takes about 6 minutes to initialise. Once initialised you can see all the training configuration details. (I'm going to ignore what hyperparameter's are for now as the training hasn't mentioned anything but they look interesting)

What’s really cool however, because this is actually a real simulation, you get the watch it train!
So, what is it doing?
DeepRacer uses Amazon SageMaker to train the model, and to do this it uses AWS RoboMaker to simulate a virtual DeepRacer (agent) on the track (environment).
Reinforcement learning training is an iterative process, the DeepRacer basically just keeps driving around the environment (track) and collects experience. This experience is then used to update the neural network (the model) and then this updated model is used as the new baseline for the next round of training.
Think about trying to learn how to drive, as you drove around your instructor would reward you with positive or negative feedback and based on this feedback you would use that experience to learn.
In our reward function, we have two input parameters, the width of the track, and our distance from the centre line
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']

Based on the track width, we create three markers that are offset from the centre line.
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
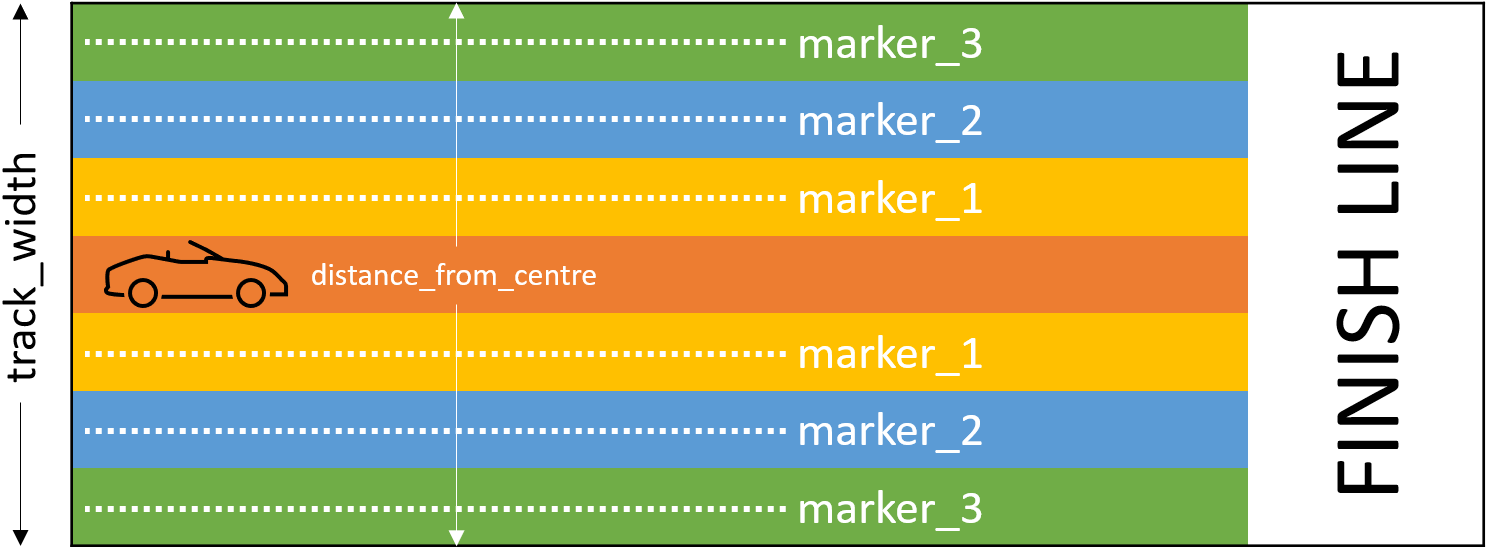
Based on the position of the car, we calculate the reward.
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
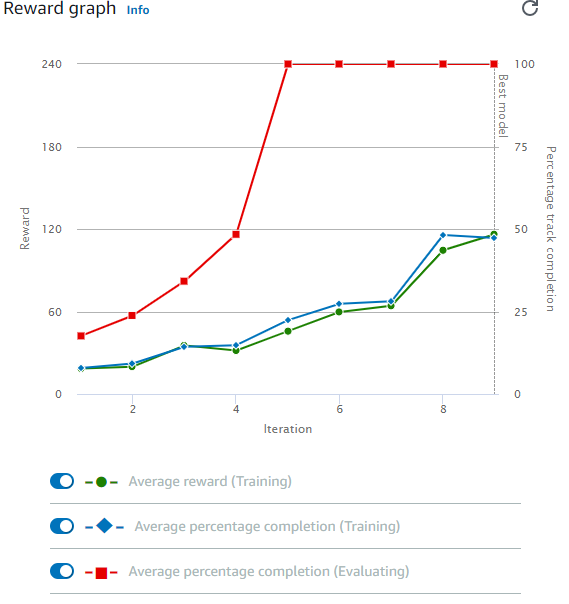
60 minutes later
Our model has finished its first training run after 60 minutes, as you can see it looks like the DeepRacer got better over time.
Evaluation
Now that we have a trained model, its time to evaluate it by having the DeepRacer (agent) participate in a race.
For this evaluation we are going to run the evaluation on the same re:Invent 2018 track in a Time Trial race with a total of 3 races.
Once the evaluation starts (it takes about 3 minutes) and we get to watch our DeepRacer go around the track. Unfortunately the video is only live streamed and you can't watch it back after the evaluation is done.
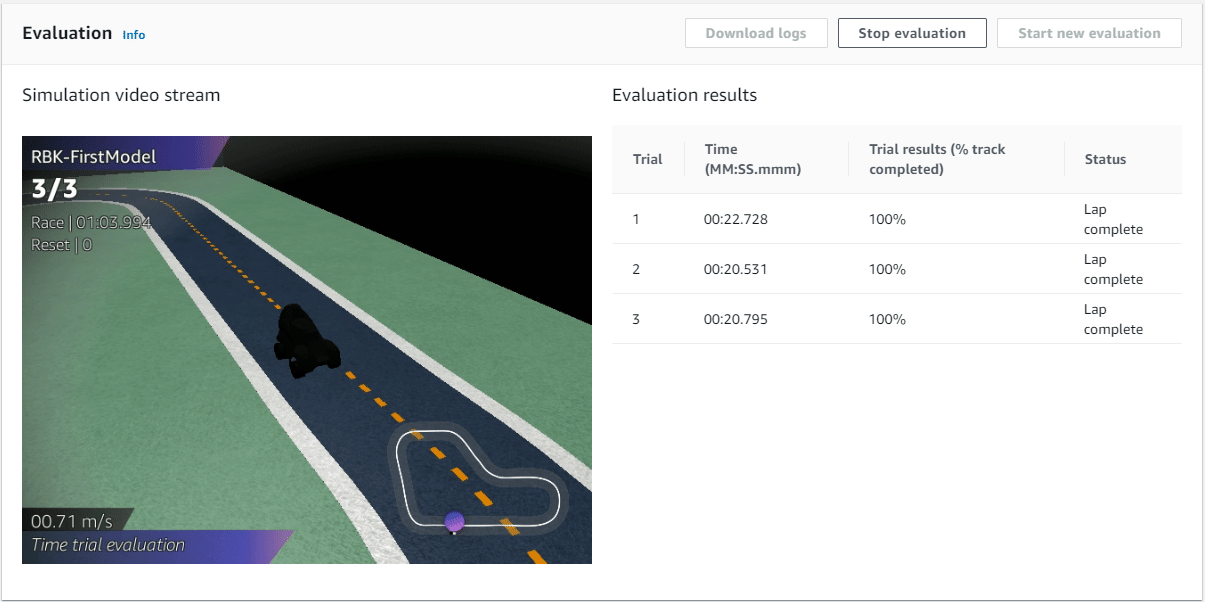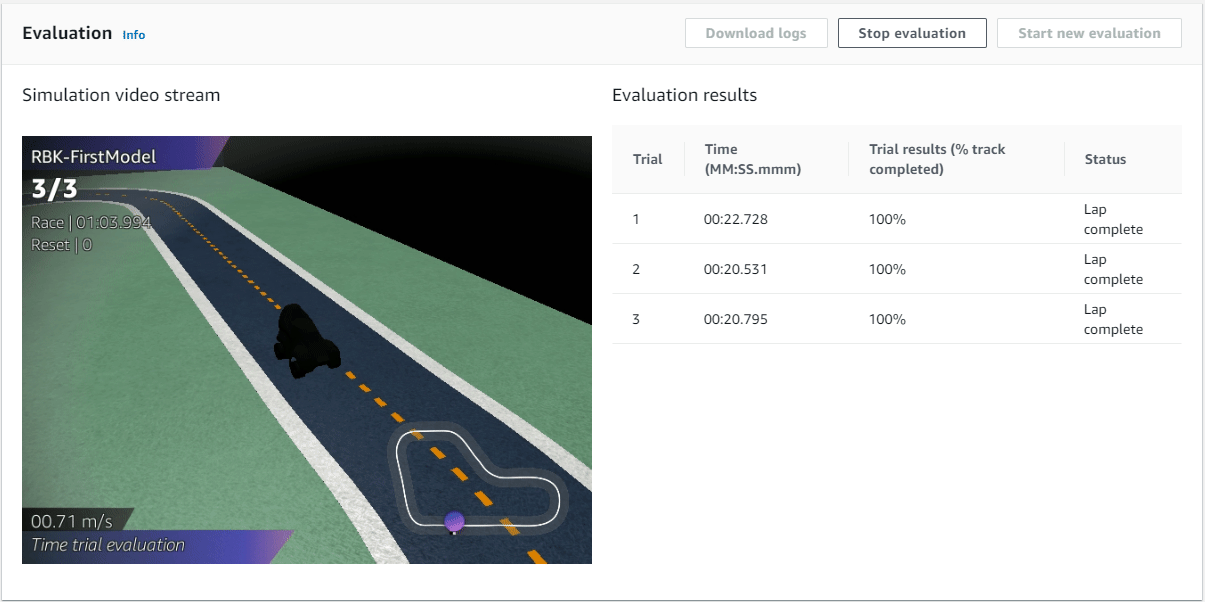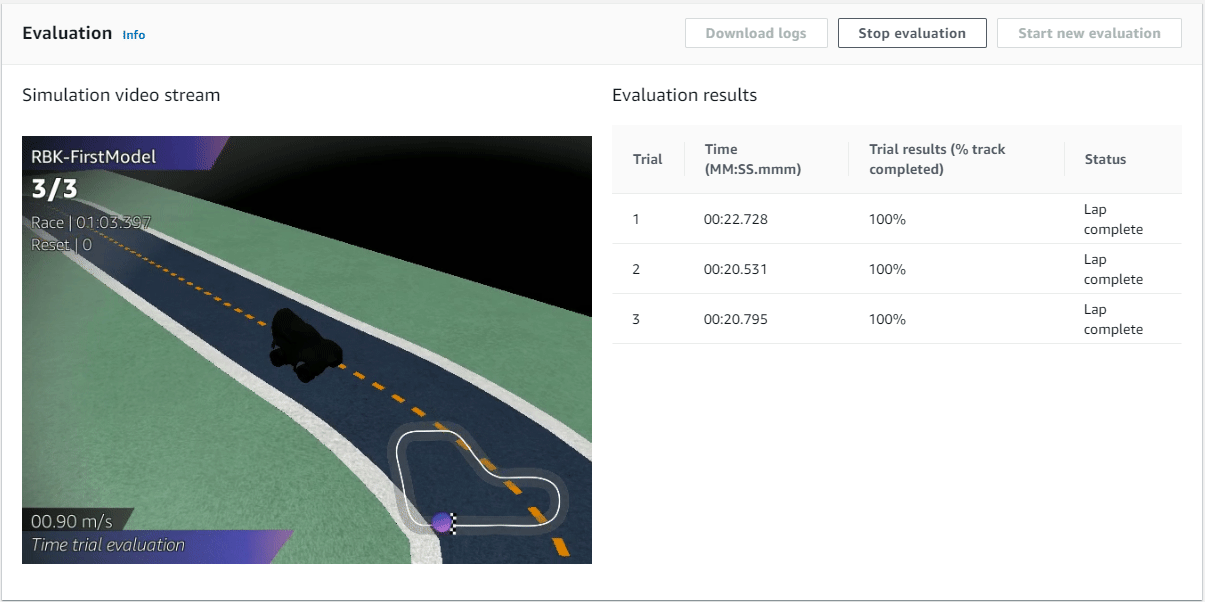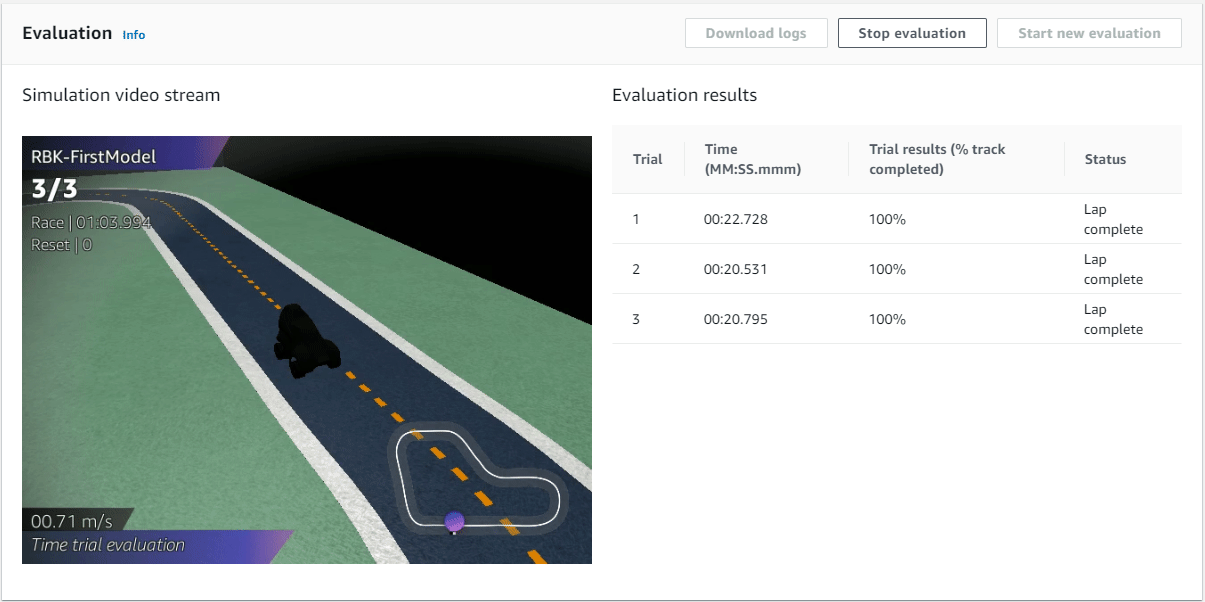
Awesome, we had a best time of just over 20 seconds. We have successfully trained a DeepRacer to drive around the track, how cool is that!
Now this has been a pretty long blog post so I’m going to split it into two posts. In the next part I will keep following the training and work to optimise the model to enhance the DeepRacer’s performance.